To define the best way how to work on projects there are some basic process models that are used every often:
waterfall model
The waterfall is split all task into the following parts:
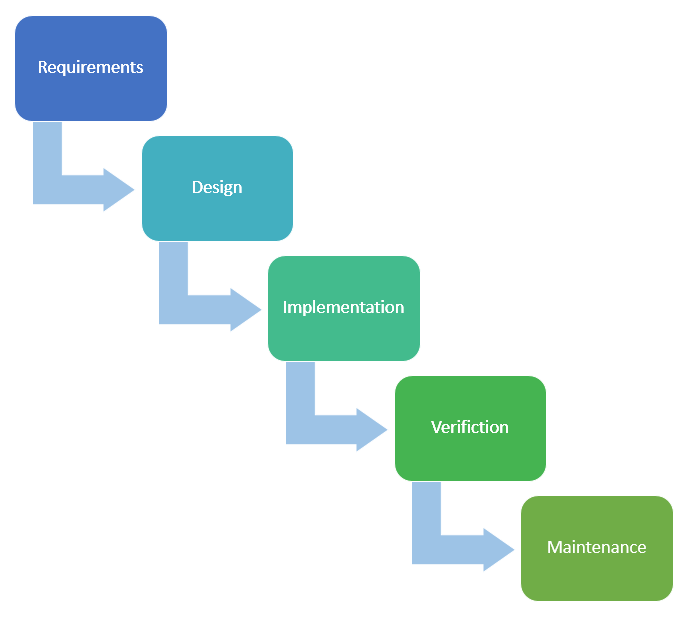
This phases define probably the most-used standard-pattern to realize a project. You start by checking out the requirements an go on by creating the first design for the implementation. Well done you give the design out to let someone implement it. To manage the quality you verify that everything is like needed and the product is ready to get used by the customer. Anyway your task is not done yet because you have to maintenance the product. For me this is the standard of every standard for implementing some developments.
spiral model
The spiral model is made to have small cycles to have more agility while developing. The following graphic will show you how this works:
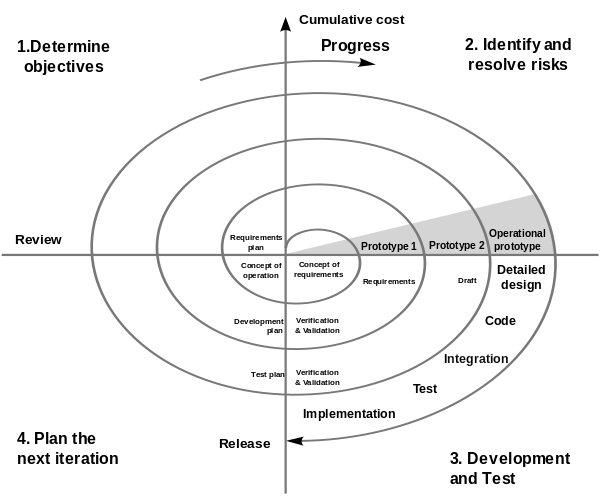
The model shows the different releases in cycles and how you work in every cycle. In every cycle you check out the needed fixes and changes requirements again and adapt your development to these changes. This will make sure that the final version is the sames that the customer wish to. Because of this re-management of everything you will need more time – but the result shine on you.
You can find the orginal-one here: Special Report CMU/SEI-2000-SR-008, July 2000.
v model
The v model provides for every implementation a single test. This concept makes sure that every single task is well done to avoid any kind of mistakes while the customers use. In this framework of implementation looks like this:

So basically you try to control every thing phase that is done on the left side by using different test-methods. For my self I do not think that you always should go with something like this because it is probably an overhead to test every single level. In some cases this is a good idea but generell I would not recommend this to you in fact to such a high test-time-expenses.
kanban
The last one that I would like to show you is the kanban. Kanban is a great system as well to work with which is like an alternativ to SCRUM. Here you have a backlog, a state of developing, an test-state and for sure the state of completion. For this a lot of users use a board that shows you what tast is in which state. With the most sofware-systems for this you can just drag and drop the task into the different states. With this you always have a great view of what is your team doing right now and the state of the task. This is pretty useful if you work in a team of developer with 3 to 8 team members. If you want to implement this I would invite you to check out the SCRUM system as well.

You must be logged in to post a comment.